Project Proposal
Problem Statement
The field of Computer Vision has seen many advances over the last few years, but we haven’t been able to achieve the same standards as human perception. In this project, we focus on the specific task of visual relationship detection to make progress towards genuine scene understanding. Our goal is to be able to detect objects of interest in an image, given a particular relationship that has been highlighted through text input. The input to the system is an image along with a textual description of an object-object relationship and the output is the image with bounding boxes around the objects that correspond to the textual input. Given the input, “plate next to pizza”, the output would be the pink bounding box on the right:
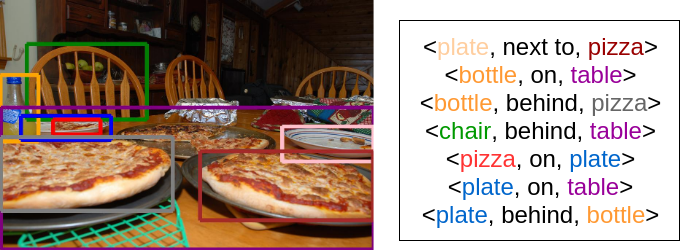
Approach
The existing implementations for visual relationship detection output all possible object-object relationships when fed an image. We intend to detect specific object pairs and a relationship predicate between them that match the given textual input while at the same time try and minimize the number of erroneous pairs our model outputs. The model to achieve the same is described in the subsequent sections.
1.1. The first step would be to identify a <subject, predicate, object> triplet from the given text input. We will be using the Stanford NLP toolkit/spacy for this task.
1.2. We would then find all possible object pairs in the image. Current state-of-the-art models for object detection achieve impressive performance by leveraging deep convolutional neural networks. We plan to use the Fast RCNN pipeline for this module.
1.3 After finding all possible object pairs, we find object pairs that correspond to the <s,o> detected in the triplet obtained from step 1.1.
1.4 We also introduce a thresholded intra-bounding box distance filter to discard pairs of <s,o> that are spatially distant in the image. This is to keep in line with our limited set of spatial predicates.
In this project, we propose an approach to learn the predicate relationship in images. We do this by using a pre-trained convolutional neural network (VGG16) and optimizing a triplet-loss function. Triplet loss is a loss function for neural networks where a baseline (anchor) input is compared to a positive input and a negative input. The distance from the baseline input to the positive input is minimized, and the distance from the baseline input to the negative input is maximized. The input to this model would be an image of our <s,o> pair. The output of this model would be class probabilities for our limited set of predicates. Due to computational limitations and time constraints, we will be using a limited set of spatial predicates to test our approach.
Tasks:
Object Detection: Returning bounding boxes around entities in the image that look like the ‘subject’ and the ‘object’ from the input description.
Object Pair Filtering: Filtering out object pairs in the image that do not have a semantically meaningful relationship between them (spatially distant objects).
Neural Network Model: Based on the positions of relevant bounding boxes with respect to each other, detect the probability of the relationship corresponding to the input predicate.
Experiments & Evaluation
We plan to evaluate our system on two publicly available datasets: Visual Relationships and Open Images.
The VR dataset contains images annotated by very diverse relationships between objects, not only human-centric ones. It has 70 relationships of various nature, such as spatial relationships (e.g. behind, next to), comparative relationships (e.g. taller than), and actions (e.g. kick, pull). There are 4000 training and 1000 test images. On average each image is annotated by 7.6 relationships. We also use the official metrics for this dataset: Recall@50 and Recall@100. These metrics require the model to output 50 or 100 relationship detections per image, and measure the percentage of ground-truth annotations that are correctly detected by these guesses (i.e. measuring recall, without considering precision).
The Open Images Dataset (OID) is a very large-scale dataset containing image-level labels, object bounding boxes, and visual relationships annotations. In total it contains 329 distinct relationship triplets and 374, 768 annotations on 100, 522 images in the training set. The metric is the weighted average of the three metrics common for visual relationship detection performance evaluation: mAP on phrase detection, mAP for relationship detection and Recall@50 for relationship detections.
We plan on adapting modules of our project from the following:
https://github.com/NSchrading/intro-spacy-nlp/blob/master/subject_object_extraction.py - Subject Object extraction from a phrase.
https://github.com/Prof-Lu-Cewu/Visual-Relationship-Detection - Visual Relationship Detection with Language Priors.
https://github.com/rbgirshick/py-faster-rcnn - Faster R-CNN
We’ll consider our project a success if our model correctly displays bounding boxes qualitatively. We expect to exploit the correlation between visual and language cues of an image to find accurate visual relationships. We also wish to experiment with how spatial context of objects and the relationships they are involved in differ.
References
- Cewu Lu, Ranjay Krishna, Michael Bernstein and Li Fei-Fei - “Visual Relationship Detection with Language Priors”
- Bo Dai, Yuqi Zhang and Dahua Lin - “Detecting Visual Relationships with Deep Relational Networks”
- Kongming Liang, Yuhong Guo, Hong Chang and Xilin Chen - “Visual Relationship Detection with Deep Structural Ranking”
- Stephan Baier, Yunpu Ma, and Volker Tresp - “Improving Visual Relationship Detection usingSemantic Modeling of Scene Descriptions”